Künstliche allgemeine Intelligenz (Artificial General Intelligence, AGI) bezeichnet eine Form der künstlichen Intelligenz, die in der Lage ist, zu verstehen, zu lernen und Wissen in einem breiten Spektrum von Aufgaben und Bereichen anzuwenden, ähnlich wie ein Mensch. Im Gegensatz zur engen KI, die sich auf spezifische Aufgaben konzentriert, kann sich die AGI an eine Vielzahl von Problemen anpassen, Kreativität zeigen und Problemlösungsfähigkeiten aufweisen, die im Allgemeinen mit menschlicher Intelligenz in Verbindung gebracht werden.
AGI stellt eine potenzielle Zukunftstechnologie dar, die nach Ansicht ihrer Befürworter in der Lage ist, den Menschen bei den meisten wirtschaftlich produktiven Aufgaben zu übertreffen und möglicherweise neue wissenschaftliche Durchbrüche zu erzielen. Obwohl es sich bei der AGI derzeit um ein theoretisches Konzept handelt, hat sie das Potenzial, zahlreiche Bereiche zu revolutionieren, von der wissenschaftlichen Entdeckung bis zur wirtschaftlichen Produktivität. Die Machbarkeit von AGI und der Zeitplan für ihre Entwicklung sind unter Forschern umstritten. OpenAI und DeepMind, die weltweit führenden KI-Forschungsorganisationen, haben sich jedoch beide ausdrücklich zur Entwicklung von AGI verpflichtet.
Eine Aktivierungsfunktion ist ein zentrales Konzept in künstlichen neuronalen Netzen (KNN) und anderen maschinellen Lernmodellen, das zur Einführung von Nichtlinearität in das Modell verwendet wird. Sie spielt eine entscheidende Rolle bei der Entscheidung, ob ein Neuron in einem neuronalen Netzwerk aktiviert wird oder nicht, basierend auf einer gewichteten Summe seiner Eingaben.
In einem typischen neuronalen Netzwerk erhält jedes Neuron eine gewichtete Summe seiner Eingaben, die durch die vorhergehende Schicht oder direkt von den Eingabedaten stammen können. Diese Summe wird dann an die Aktivierungsfunktion übergeben, die sie verarbeitet und ein Ausgabesignal erzeugt, das dann an die nächsten Neuronen weitergeleitet wird.
Wichtige Eigenschaften
Nichtlinearität:
Ohne eine Aktivierungsfunktion wäre ein neuronales Netzwerk lediglich eine lineare Funktion, was seine Fähigkeit zur Modellierung komplexer Zusammenhänge stark einschränken würde.
Gradientenberechnung:
Die Wahl der Aktivierungsfunktion beeinflusst die Fähigkeit des Netzwerks, Gradienten effizient zu berechnen und während des Trainings zu propagieren.
Häufige Typen:
Zu den verbreiteten Aktivierungsfunktionen gehören die Sigmoid-Funktion, die tanh-Funktion, die ReLU (Rectified Linear Unit) und ihre Varianten wie Leaky ReLU und ELU (Exponential Linear Unit).
Anwendungen
Aktivierungsfunktionen finden Anwendung in verschiedenen Bereichen des maschinellen Lernens und der künstlichen Intelligenz, einschließlich Bilderkennung, natürlicher Sprachverarbeitung, Sprachübersetzung und Robotik.
Die Wahl der Aktivierungsfunktion hängt oft von der spezifischen Problemstellung, der Architektur des neuronalen Netzes und den Anforderungen an die Berechnungseffizienz ab.
Voreingenommenheit ist, einfach ausgedrückt, eine unfaire Bevorzugung oder Voreingenommenheit einer Person oder Gruppe gegenüber einer anderen. Sie kann zu einer ungleichen Behandlung oder einem Mangel an Fairness bei der Entscheidungsfindung führen. Im Zusammenhang mit künstlicher Intelligenz und maschinellem Lernen liegt eine Voreingenommenheit vor, wenn das Computersystem auf der Grundlage der Daten, auf die es trainiert wurde, Entscheidungen trifft, die eine Gruppe oder ein Ergebnis gegenüber einer anderen Gruppe bevorzugen und damit bestehende Ungleichheiten oder Stereotypen widerspiegeln.
Beispiele für solche Verzerrungen sind KI-gestützte Strafverfolgungssoftware, die bei ähnlichen Verbrechen für schwarze Straftäter längere Haftstrafen empfiehlt als für weiße Straftäter, oder Gesichtserkennungssoftware, die weiße Gesichter besser erkennt als schwarze Gesichter. Diese Unzulänglichkeiten sind häufig auf soziale Ungleichheiten in den von diesen Systemen verwendeten Trainingsdaten zurückzuführen. Heutige KI-Systeme funktionieren in erster Linie als Musterreplikatoren, die große Datenmengen mithilfe neuronaler Netze verarbeiten, um Muster zu erkennen. Wenn die Trainingsdaten ein Ungleichgewicht enthalten, wie z. B. eine höhere Anzahl weißer Gesichter im Vergleich zu schwarzen Gesichtern oder historische Strafverfolgungsdaten, die ein Ungleichgewicht zwischen schwarzen und weißen Straftätern zeigen, können maschinelle Lernsysteme unbeabsichtigt diese Vorurteile erlernen und aufrechterhalten, wodurch Ungleichheiten automatisiert werden.
Cross-Entropy baut auf der Idee der Entropy auf und misst, wie gut eine Wahrscheinlichkeitsverteilung (z. B. die Vorhersagen eines Modells) mit der tatsächlichen Verteilung (den echten Labels) übereinstimmt.
Beispiel:
Ein Modell sagt vorher, wie wahrscheinlich etwas ist, z. B.:
- Ein Modell soll vorhersagen, ob ein Bild eine Katze (Label: 1) oder keine Katze (Label: 0) zeigt.
- Wenn das Modell sehr sicher ist (z. B. sagt: 90 % Wahrscheinlichkeit für „Katze“), und es stimmt, dann ist der Fehler gering.
- Wenn das Modell unsicher ist (z. B. sagt: 50 % Wahrscheinlichkeit für „Katze“) oder falsch liegt, ist der Fehler hoch.
Cross-Entropy misst diesen Fehler zwischen den vorhergesagten Wahrscheinlichkeiten und den tatsächlichen Labels.
Cross-Entropy wird verwendet, um:
- Unsicherheit zu bestrafen: Wenn das Modell eine falsche Vorhersage macht oder unsicher ist, wird ein höherer Fehlerwert erzeugt.
- Genaue Vorhersagen zu belohnen: Wenn das Modell sehr sicher ist (z. B. eine hohe Wahrscheinlichkeit für die richtige Klasse), ist der Fehler gering.
Es hilft Modellen, schneller zu lernen, indem es ihnen beibringt, realistische Wahrscheinlichkeiten vorherzusagen.
Mathematische Sicht:
Die Cross-Entropy wird berechnet als:


- Für ein korrektes Label y=1 bestraft die Cross-Entropy, wenn y^ klein ist (d. h. die Wahrscheinlichkeit für die richtige Klasse ist niedrig).
- Für ein falsches Label y=0 bestraft sie, wenn y^ groß ist (d. h. das Modell gibt der falschen Klasse zu hohe Wahrscheinlichkeit).
Beispiel mit zwei Klassen
- Wahre Klasse: y=1 (z. B. Katze)
- Modellvorhersage: y^=0.9
- Cross-Entropy: H=−1⋅log(0.9)=0.105 (geringer Fehler, gute Vorhersage).
Aber wenn das Modell unsicher ist, z. B. y^=0.5, dann:
H=−log(0.5)=0.693 (höherer Fehler, weil das Modell unsicher ist)
Mehrere Klassen
In Aufgaben mit mehreren Klassen (z. B. Hund, Katze, Vogel), wird die Cross-Entropy über alle Klassen summiert, wobei der Schwerpunkt auf der Wahrscheinlichkeit für die richtige Klasse liegt.
Zusammenhang
Entropy misst die Unsicherheit in Daten.
Cross-Entropy misst, wie gut die vorhergesagten Wahrscheinlichkeiten eines Modells mit den wahren Labels übereinstimmen.
Sie ist ein beliebtes Loss-Function-Maß in maschinellem Lernen, weil sie Modelle dazu anregt, möglichst genaue und sichere Wahrscheinlichkeiten vorherzusagen.
Häufig benötigen maschinelle Lernsysteme menschliche Kommentatoren, um Daten zu beschriften oder zu beschreiben, bevor sie für das Training verwendet werden können. Bei der Entwicklung selbstfahrender Autos beispielsweise müssen menschliche Mitarbeiter Dashcam-Videos mit Anmerkungen versehen, indem sie Autos, Fußgänger, Fahrräder usw. einzeichnen, um dem System beizubringen, verschiedene Straßenelemente zu erkennen.
Diese Aufgabe wird häufig an Leiharbeiter im globalen Süden delegiert, die in unsicheren Beschäftigungsverhältnissen arbeiten und Löhne erhalten, die kaum über dem Armutsniveau liegen. In einigen Fällen kann diese Arbeit sehr belastend sein. So mussten kenianische Arbeiter Inhalte mit Gewalt, explizitem Material und Hassreden ansehen und kennzeichnen, um ChatGPT zu trainieren, die Beschäftigung mit solchen Themen zu vermeiden.
Entropy ist ein Konzept aus der Informationstheorie und misst die Unsicherheit oder den Informationsgehalt in einer Datenmenge. Einfach gesagt, sie hilft uns zu verstehen, wie „unordentlich“ oder „ungeordnet“ die Daten sind.
Beispiel
- Eine Schale ist mit farbigen Kugeln (rot, blau, grün) gefüllt.
- Wenn alle Kugeln rot sind, gibt es keine Unsicherheit: Zieht man eine Kugel, weiß man genau, was man bekommt. Die Entropy ist niedrig (oder null).
- Wenn die Kugeln gleichmäßig auf Rot, Blau und Grün verteilt sind, ist die Unsicherheit am höchsten: Man weiß nicht, welche Farbe man bekommt, wenn man eine Kugel zieht. Die Entropy ist hoch.
Im maschinellen Lernen
Entropy wird oft verwendet, um Entscheidungen zu optimieren, z. B. bei Entscheidungsbäumen:
- Hohe Entropy bedeutet, die Daten sind gemischt und es gibt keine klare Trennung (z. B. verschiedene Klassen sind schwer zu unterscheiden).
- Niedrige Entropy bedeutet, die Daten sind gut getrennt, und es ist einfacher, eine Entscheidung zu treffen (z. B. eine Klasse zuzuordnen).
Ein Algorithmus versucht oft, die Entropy zu **minimieren**, indem er die Daten so trennt, dass sie möglichst „geordnet“ oder eindeutig werden. Dies hilft, bessere Vorhersagen zu treffen.
Mathematische Sicht
Die Entropy wird durch eine Formel berechnet:
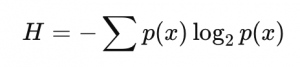
- p(x): Wahrscheinlichkeit eines Ereignisses x (z. B. wie oft eine Klasse in den Daten vorkommt).
- Je höher die Wahrscheinlichkeit p(x), desto geringer der Beitrag zur Unsicherheit.
Entropy ist ein Maß für die Unordnung in Daten und hilft Algorithmen, bessere Entscheidungen zu treffen.
Multivariate Analysen sind statistische Methoden, die verwendet werden, um die Beziehung zwischen mehreren Variablen zu untersuchen. Im Gegensatz zu univariaten Analysen, die sich nur auf eine Variable konzentrieren, betrachten multivariate Analysen mehrere Variablen gleichzeitig.
Multivariate Analysen können verwendet werden, um komplexe Datenmuster zu identifizieren, Zusammenhänge zwischen Variablen zu untersuchen, Vorhersagemodelle zu erstellen und Hypothesen zu testen. Einige Beispiele für multivariate Analysemethoden sind die lineare Regression, die Faktorenanalyse, die Clusteranalyse und die Diskriminanzanalyse.
Eine Prädiktorvariable ist eine unabhängige Variable in einem statistischen Modell, die verwendet wird, um Vorhersagen über eine abhängige Variable zu treffen. In der Data Science werden Prädiktorvariablen häufig verwendet, um Vorhersagemodelle zu erstellen, die auf historischen Daten basieren. Diese Modelle können dann verwendet werden, um Vorhersagen über zukünftige Ereignisse oder Trends zu treffen. Beispielsweise könnte die Anzahl der Stunden, die eine Person pro Woche arbeitet, eine Prädiktorvariable sein, die verwendet wird, um das Einkommen dieser Person vorherzusagen. Andere Beispiele für Prädiktorvariablen könnten Alter, Geschlecht, Bildungsniveau oder geografische Region sein.
Die Sigmoid-Funktion ist eine spezifische Aktivierungsfunktion, die häufig in künstlichen neuronalen Netzen verwendet wird, um Nichtlinearität einzuführen und die Ausgabe jedes Neurons zu normalisieren. Sie nimmt einen skalaren Eingabewert und transformiert ihn in einen Wert zwischen 0 und 1. Diese Eigenschaft macht sie besonders nützlich für Probleme, bei denen die Wahrscheinlichkeit oder die Wahrscheinlichkeitsverteilung der Ausgabe interpretiert werden soll.Die mathematische Form der Sigmoid-Funktion ist definiert als:
\sigma(x) = \frac{1}{1 + e^{-x}}
Hierbei ist x die gewichtete Summe der Eingaben eines Neurons. Wenn x groß und positiv ist, nähert sich \sigma(x) 1 an, während es sich bei großen negativen Werten 0 annähert. Dies ermöglicht es, die Aktivierung eines Neurons zu steuern und zu normalisieren.
Eigenschaften
Sättigung
Die Sigmoid-Funktion sättigt bei extremen Werten von \( x \), was zu einem Problem führen kann, das als „Gradientenverschwinden“ bekannt ist. Dies kann das Training tiefer neuronaler Netze erschweren.
Anwendung
Obwohl die Sigmoid-Funktion aufgrund des Sättigungsproblems in tiefen Netzwerken weniger häufig verwendet wird, findet sie immer noch Anwendung in Modellen wie logistischer Regression und als Basiskomponente für andere Aktivierungsfunktionen wie die tanh-Funktion.
Interpretierbarkeit
Ihre Ausgabe zwischen 0 und 1 wird oft als Wahrscheinlichkeit interpretiert, was sie besonders geeignet für Klassifikationsprobleme macht, bei denen die Vorhersage einer binären Entscheidung entspricht (z.B. ja oder nein).
Alternative Aktivierungsfunktionen:
Aufgrund der Nachteile der Sigmoid-Funktion haben ReLU (Rectified Linear Unit) und seine Varianten wie Leaky ReLU und ELU (Exponential Linear Unit) in vielen modernen Anwendungen an Popularität gewonnen, da sie effizientere Gradientenberechnungen und bessere Konvergenzeigenschaften bieten können.
Die Wahl der Aktivierungsfunktion hängt von der spezifischen Problemstellung, der Netzwerkarchitektur und den Anforderungen an die Modellleistung ab.
„Text-to-Speech“ (TTS), auf Deutsch „Text-zu-Sprache“, bezeichnet eine Technologie, die geschriebenen Text in gesprochene Sprache umwandelt. TTS-Systeme ermöglichen es Computern, Texte laut vorzulesen, wodurch sie in vielen Anwendungen, einschließlich Sprachassistenten, E-Book-Readern und Navigationssystemen, eingesetzt werden.
Moderne TTS-Systeme verwenden häufig neuronale Netzwerkarchitekturen, insbesondere Deep Learning, um natürlicher klingende menschliche Stimmen zu erzeugen. Dies unterscheidet sich von älteren Systemen, die auf konkatenierte Audiosegmente angewiesen waren und oft weniger natürlich klangen.
Die Qualität und Natürlichkeit von TTS-Systemen haben sich in den letzten Jahren erheblich verbessert, und sie können heute in verschiedenen Sprachen, Dialekten und Stimmlagen Sprache generieren. Einige fortschrittliche Systeme sind sogar in der Lage, Emotionen oder besondere Betonungen in die generierte Sprache einzufügen.