
Im Bereich des Unsupervised Learnings gibt es verschiedene Ansätze, um Muster in Daten zu erkennen. Einer dieser Ansätze ist das hierarchische Clustering.
Beim hierarchischen Clustering werden die Datenpunkte schrittweise zu Gruppen zusammengefasst, wobei ähnliche Datenpunkte in der gleichen Gruppe landen. Dabei wird eine Hierarchie von Gruppen gebildet, die sich entweder von oben nach unten (agglomeratives Clustering) oder von unten nach oben (divisives Clustering) aufbaut.
Beim agglomerative Clustering (Bottom-up) ist zunächst jeder Datenpunkt ein eigener Cluster, die dann schrittweise zu größeren Clustern zusammengefasst werden, bis alle Datenpunkte in einer großen Gruppe vereint sind. Das divisive Clustering (Top-down) hingegen beginnt mit allen Datenpunkten in einem Cluster und teilt diese dann schrittweise in kleinere Cluster auf, bis jeder Datenpunkt seinen eigenen Cluster bildet.
Beide Verfahren haben Vor- und Nachteile und eignen sich für unterschiedliche Anwendungsbereiche. Beim hierarchischen Clustering ist es wichtig, die richtige Distanzmetrik und Agglomerationsmethode zu wählen, um aussagekräftige Ergebnisse zu erhalten.
Insgesamt bietet das hierarchische Clustering eine flexible Methode zur Identifikation von Mustern in ungelabelten Daten und kann bei der Datenaufbereitung und -analyse helfen.
Dendrogramm
Hierarchische Clusterverfahren führen zu Datensätzen, die Dendrogramme genannt werden. Ein Dendrogramm ist ein Diagramm, das die hierarchische Struktur von Objekten oder Daten darstellt. Es wird verwendet, um Gruppen von ähnlichen Objekten zu identifizieren und zu analysieren. Es kann dabei helfen, Muster in den Daten zu erkennen und Zusammenhänge zwischen verschiedenen Variablen aufzuzeigen.
Ein Dendrogramm besitzt eine Baumstruktur und setzt sich aus senkrechten Linien zusammen, welche die Ähnlichkeit der Objekte darstellen, sowie auch horizontalen Linien, welche die Verbindungen zwischen den Objekten anzeigen. Die Linien werden auf Basis der Ähnlichkeit zwischen den Objekten gezogen, wobei ähnlichere Objekte näher beieinander platziert werden und weniger ähnliche weiter voneinander entfernt dargestellt werden.Die Wurzel enthält den gesamten Datensatz. Jede weitere Stufe besteht aus einem Knoten, an dem die Daten in zwei Sätze geteilt werden, bis am unteren Ende die einzelnen Datenpunkte, die Blätter, übrig bleiben.
Insgesamt ist das Dendrogramm ein nützliches Werkzeug für die Datenanalyse und kann dazu beitragen, komplexe Informationen auf eine übersichtliche Weise darzustellen.
Was sind die Vorteile eines Dendrogramms?
Ein Dendrogramm bietet Vorteile, wenn es darum geht, komplexe Daten zu visualisieren und zu interpretieren. Hier sind einige der wichtigsten Vorteile:
- Übersichtlichkeit: Ein Dendogramm kann große Menge an Daten auf eine übersichtliche Art und Weise darstellen. Es zeigt die Beziehungen zwischen den Datenpunkten auf einen Blick.
- Strukturierung: Ein Dendrogramm ordnet die Datenpunkte hierarchisch nach ihrer Ähnlichkeit oder Entfernung zueinander an. Dadurch können Muster und Strukturen in den Daten leichter erkannt werden.
- Vergleichbarkeit: Durch die Verwendung von Farben oder anderen visuellen Elementen können verschiedene Gruppen oder Kategorien von Datenpunkten leichter verglichen werden.
- Interpretierbarkeit: Ein Dendogramm kann dazu beitragen, komplexe Zusammenhänge zwischen den Datenpunkten zu verstehen und zu interpretieren.
- Flexibilität: Ein Dendogramm kann für verschiedene Arten von Daten verwendet werden, einschließlich numerischer, kategorialer oder textbasierter Daten.
Insgesamt ist ein Dendogramm ein leistungsstarkes Werkzeug zur Visualisierung und Analyse von Daten, das in vielen Bereichen wie Biologie, Sozialwissenschaften, Wirtschaft und Technik eingesetzt wird.
Dendrogramm in R erstellen
Dieser Code erstellt ein einfaches Dendrogramm. Der Datensatz besteht aus Schüler der Grundschule und Oberstufe, die mit Name und Alter angegeben sind. Die Distanzmatrix wird basierend auf der euklidischen Distanz berechnet, und das hierarchische Clustering verwendet die Average-Linkage-Methode.
# Datensatz erstellen
schueler <- data.frame(
Name = c("Anna", "Ben", "Carla", "David", "Eva", "Felix", "Greta", "Hans", "Ines", "Jakob"),
Alter = c(8, 9, 9, 17, 18, 8, 10, 17, 19, 16),
Gruppe = c("Grundschule", "Grundschule", "Grundschule", "Oberstufe", "Oberstufe", "Grundschule", "Grundschule", "Oberstufe", "Oberstufe", "Oberstufe")
)
# Distanzmatrix basierend auf dem Alter der Schüler berechnen
dist_matrix <- dist(schueler$Alter, method = "euclidean")
# hierarchisches Clustering durch
hc <- hclust(dist_matrix, method = "average")
# Dendrogramm zeichnen
par(mar = c(8, 4, 2, 2))
plot(hc, main = "Dendrogramm von Grundschul- und Oberstufenschülern", xlab = "", ylab = "", axes = FALSE, labels = FALSE)
# Achsenbeschriftungen hinzufügen
mtext(side = 1, text = schueler$Name[hc$order], at = 1:nrow(schueler), las = 2, line = 1)
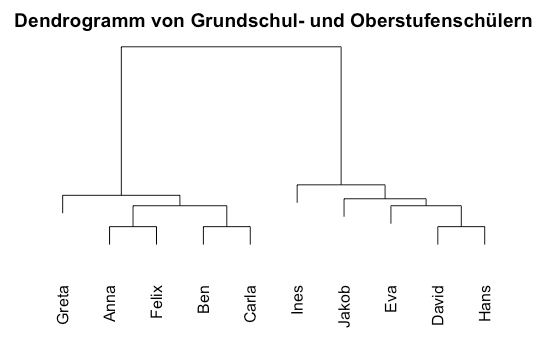
Das Dendrogramm zeigt deutlich zwei Cluster. Auf der linken Seite finden sich die Grundschüler, auf der rechten die Oberstufenschüler. Die Schüler in den beiden Clustern sind jeweils weiter nach ihrem Alter unterteilt. Gleichaltrige Schüler, wie zum Beispiel Anna und Felix sind in einem Cluster zusammengefasst.
Schreibe einen Kommentar