Entropy ist ein Konzept aus der Informationstheorie und misst die Unsicherheit oder den Informationsgehalt in einer Datenmenge. Einfach gesagt, sie hilft uns zu verstehen, wie „unordentlich“ oder „ungeordnet“ die Daten sind.
Beispiel
- Eine Schale ist mit farbigen Kugeln (rot, blau, grün) gefüllt.
- Wenn alle Kugeln rot sind, gibt es keine Unsicherheit: Zieht man eine Kugel, weiß man genau, was man bekommt. Die Entropy ist niedrig (oder null).
- Wenn die Kugeln gleichmäßig auf Rot, Blau und Grün verteilt sind, ist die Unsicherheit am höchsten: Man weiß nicht, welche Farbe man bekommt, wenn man eine Kugel zieht. Die Entropy ist hoch.
Im maschinellen Lernen
Entropy wird oft verwendet, um Entscheidungen zu optimieren, z. B. bei Entscheidungsbäumen:
- Hohe Entropy bedeutet, die Daten sind gemischt und es gibt keine klare Trennung (z. B. verschiedene Klassen sind schwer zu unterscheiden).
- Niedrige Entropy bedeutet, die Daten sind gut getrennt, und es ist einfacher, eine Entscheidung zu treffen (z. B. eine Klasse zuzuordnen).
Ein Algorithmus versucht oft, die Entropy zu **minimieren**, indem er die Daten so trennt, dass sie möglichst „geordnet“ oder eindeutig werden. Dies hilft, bessere Vorhersagen zu treffen.
Mathematische Sicht
Die Entropy wird durch eine Formel berechnet:
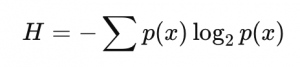
- : Wahrscheinlichkeit eines Ereignisses (z. B. wie oft eine Klasse in den Daten vorkommt).
- Je höher die Wahrscheinlichkeit p(x, desto geringer der Beitrag zur Unsicherheit.
Entropy ist ein Maß für die Unordnung in Daten und hilft Algorithmen, bessere Entscheidungen zu treffen.